KafkaConsumer消费位移管理
一、概念
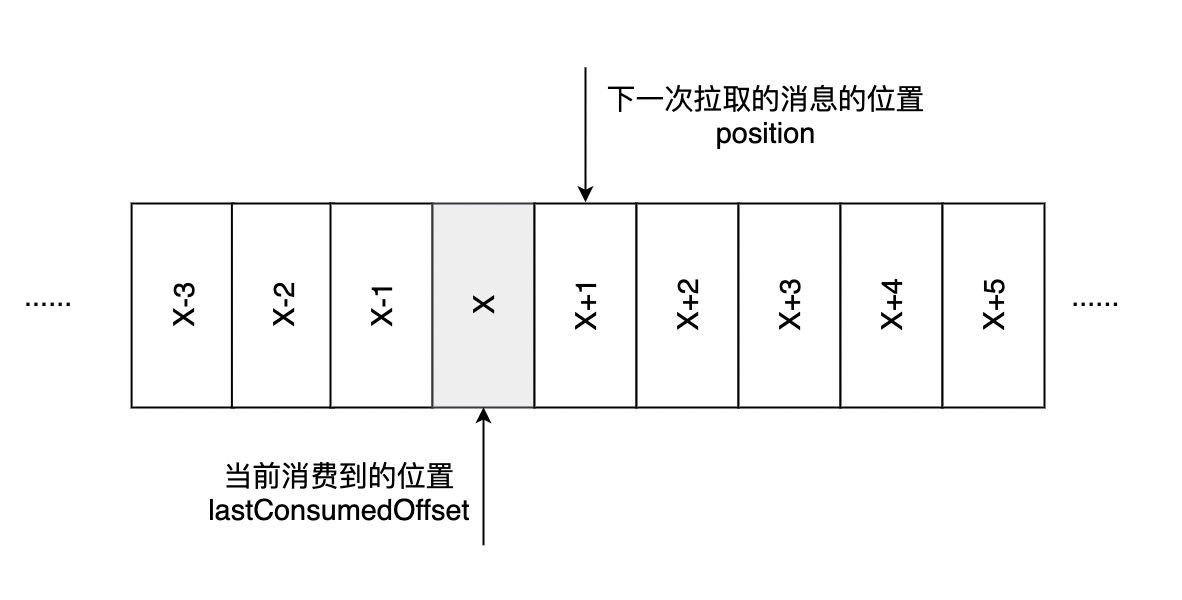
- 偏移量 消息在分区中的位置。
- 消费位移 消费者消费到的位置,从上图看是position,指下一次拉取的消息的开始位置。
二、消费位移提交
1.提交的方式
- 自动提交
- 默认的提交方式,由消费者客户端参数
enable.auto.commit决定,默认值为true; - 定期提交,提交周期有客户端参数
auto.commit.interval.ms配置,默认为5秒; - 问题:存在消息重复消费和丢失的问题。
- 默认的提交方式,由消费者客户端参数
- 手动提交,消费者客户端参数
enable.auto.commit配置为false- 同步提交
- 异步提交
2.手动同步提交位移
直接看同步提交的demo,使用 KafkaConsumer.commitSync() 的无参方法提交:
public class OffsetCommitSync {
private static final String BROKER_LIST = "localhost:9092";
private static final String TOPIC = "topic-demo";
private static final String GROUP = "group.demo";
private static AtomicBoolean isRunning = new AtomicBoolean(true);
/** 消费者端配置参数 */
private static Properties initConfig() {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_LIST);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP);
properties.put(ConsumerConfig.CLIENT_ID_CONFIG, "consumer.client.id.demo");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 非自动提交
return properties;
}
public static void main(String[] args) {
Properties properties = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC));
try {
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println("topic=" + record.topic() + ", partition=" + record.partition()
+ ", offset=" + record.offset() + ",");
System.out.println("key=" + record.key() + ", value=" + record.value());
}
consumer.commitSync(); // 同步提交消费位移
}
} catch (Exception e) {
log.error("occur exception", e);
} finally {
consumer.close();
}
}
}
可以看到,手动同步提交消费位移的方式是先对拉取到的每一条消息作相应的逻辑处理,再对整个消息集作同步提交。 下面对以上的同步提交方式作改进,优化为批量处理和批量提交:
public static void main(String[]args){
Properties properties=initConfig();
KafkaConsumer<String, String> consumer=new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC));
try{
final int minBatchSize=200;
List<ConsumerRecord> buffer=new ArrayList<>();
while(isRunning.get()){
ConsumerRecords<String, String> records=consumer.poll(Duration.ofMillis(1000));
for(ConsumerRecord<String, String> record:records){
buffer.add(record);
}
if(buffer.size()>=minBatchSize){
// do some logical processing with buffer
consumer.commitSync(); // 批量处理与位移提交
buffer.clear();
}
}
}catch(Exception e){
log.error("occur exception",e);
}finally{
consumer.close();
}
}
这两种同步提交实现都存在消息重复消费的问题,如果在业务逻辑处理完成之前,并且在同步位移提交前,程序崩溃,那么程序恢复后,又只能从上一次位移提交的地方重新拉取消息消费,这就出现了重复消费的问题。
如果在同步提交位移的过程中,需要更细粒度、更精准的提交,则可以使用 commitSync 的带参方法,以分区的粒度提交消费位移:
// KafkaConsumer类
@Override
public void commitSync(final Map<TopicPartition, OffsetAndMetadata> offsets){
commitSync(offsets,Duration.ofMillis(defaultApiTimeoutMs));
}
按照分区粒度提交消费位移的示例如下:
public static void main(String[]args){
Properties properties=initConfig();
KafkaConsumer<String, String> consumer=new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC));
try{
while(isRunning.get()){
ConsumerRecords<String, String> records=consumer.poll(Duration.ofMillis(1000));
for(TopicPartition partition:records.partitions()){
List<ConsumerRecord<String, String>>partitionRecords=records.records(partition);
for(ConsumerRecord<String, String> record:partitionRecords){
// do some logical processing
}
long lastConsumedOffset=partitionRecords.get(partitionRecords.size()-1).offset();
consumer.commitSync(Collections.singletonMap(partition,
new OffsetAndMetadata(lastConsumedOffset+1))); // 按照分区提交消费位移, position
}
}
}catch(Exception e){
log.error("occur exception",e);
}finally{
consumer.close();
}
}
3.手动异步提交位移
这种提交方式在执行时不会阻塞消费者线程,在提交消费位移的结果还未返回之前,可能就开始了新一次的消息拉取操作。异步提交可以使消费者的性能得到相对的增强。
// KafkaConsumer类
public void commitAsync()
public void commitAsync(OffsetCommitCallback callback)
public void commitAsync(final Map<TopicPartition, OffsetAndMetadata> offsets,OffsetCommitCallback callback)
下面给出异步提交回调的示例,位移提交完成后回调 OffsetCommitCallback.onComplete 方法:
public static void main(String[]args){
Properties properties=initConfig();
KafkaConsumer<String, String> consumer=new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC));
try{
while(isRunning.get()){
ConsumerRecords<String, String> records=consumer.poll(Duration.ofMillis(1000));
for(ConsumerRecord<String, String> record:records){
System.out.println("topic="+record.topic()+", partition="+record.partition()
+", offset="+record.offset()+",");
System.out.println("key="+record.key()+", value="+record.value());
}
// 异步提交消费位移
consumer.commitAsync((offsets,exception)->{
if(exception==null){
System.out.println(offsets);
}else{
log.error("fail to commit offsets {}",offsets,exception);
}
});
}
}catch(Exception e){
log.error("occur exception",e);
}finally{
consumer.close();
}
}
三、指定位移消费
1. auto.offset.reset参数
上面介绍了消费位移提交的不同方式,正是由于消费位移的持久化,才能使消费者在关闭、崩溃或者再均衡的时候,可以让接替的消费者能够根据存储的消费位移继续进行消费。
然而,当一个新的消费组建立的时候,根据没有可以查找的消费位移;或者消费组内的一个新消费者订阅了一个新的主题,它也没有可以查找的消费位移;当 Kafka 内部消费位移主题 __consuemr_offset
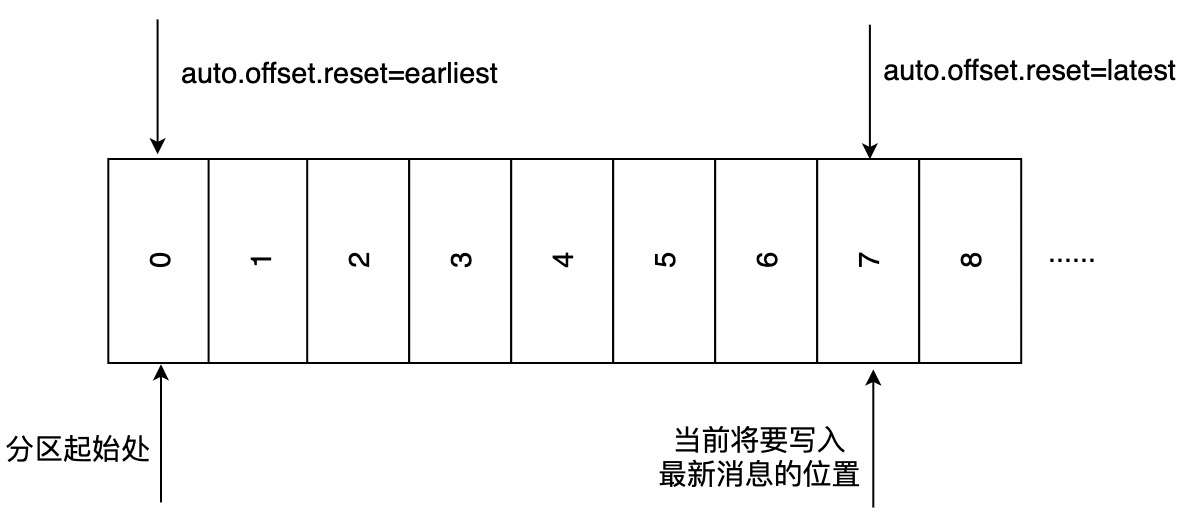
中有关这个消费组的位移信息过期而被删除后,也没有可以查找的消费位移。 在 Kafka 中每当消费者查找不到所记录的消费位移时,会根据消费者客户端参数 auto.offset.reset
的配置来决定从何处开始进行消费,默认值是 latest ,表示从分区末尾开始消费消息,参考下图,消费者会从7位置开始消费(7是下一条消息要写入的位置),即从7位置开始拉取消息。如果 auto.offset.reset
配置为 earliest ,则消费者从起始处0开始消费。
 除了查找不到消费位移,位移越界也会触发
除了查找不到消费位移,位移越界也会触发 auto.offset.reset 参数的执行,这个在下面介绍指定位移消费的时候会提及。
2.指定位移消费seek
KafkaConsumer.seek() 方法提供了对消费位移进行细粒度控制的功能,使程序可以从特定的位移处开始拉取消息。
public void seek(TopicPartition partition,long offset)
下面给出 seek() 方法的具体使用demo:
public class SeekDemoAssignment {
private static final String BROKER_LIST = "localhost:9092";
private static final String TOPIC = "topic-demo";
private static final String GROUP = "group.demo";
private static AtomicBoolean isRunning = new AtomicBoolean(true);
/** 消费者端参数配置 */
private static Properties initConfig() {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_LIST);
properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP);
properties.put(ConsumerConfig.CLIENT_ID_CONFIG, "consumer.client.id.demo");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
return properties;
}
public static void main(String[] args) {
Properties properties = initConfig();
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC));
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) { // 如果不为0,则说明该消费者已经成功分配到了分区
consumer.poll(Duration.ofMillis(100));
assignment = consumer.assignment();
}
for (TopicPartition topicPartition : assignment) {
consumer.seek(topicPartition, 10);
}
while (isRunning.get()) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.offset() + ":" + record.value());
}
}
}
}
如果消费组内的消费者在启动的时候能够找到消费位移,除非发生位移越界,否则 auto.offset.reset 参数不会生效,如果此时想指定从分区开头或末尾开始消费消息,则可以如下实现:
public static void main(String[]args){
Properties properties=initConfig();
KafkaConsumer<String, String> consumer=new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC));
Set<TopicPartition> assignment=new HashSet<>();
while(assignment.size()==0){
consumer.poll(Duration.ofMillis(100));
assignment=consumer.assignment();
}
// 从分区末尾消费
Map<TopicPartition, Long> offsets=consumer.endOffsets(assignment);
for(TopicPartition topicPartition:assignment){
consumer.seek(topicPartition,offsets.get(topicPartition));
}
while(isRunning.get()){
ConsumerRecords<String, String> records=consumer.poll(Duration.ofMillis(1000));
for(ConsumerRecord<String, String> record:records){
System.out.println(record.offset()+":"+record.value());
}
}
}
如果有时候不知道特定的消费位置,却知道一个相关的时间点,想消费某个时间点之后的消息。可以如下实现:
// 通过时间戳查询对应分区的分区位置
public Map<TopicPartition, OffsetAndTimestamp> offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch)
public static void main(String[]args){
Properties properties=initConfig();
KafkaConsumer<String, String> consumer=new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC));
Set<TopicPartition> assignment=new HashSet<>();
while(assignment.size()==0){
consumer.poll(Duration.ofMillis(100));
assignment=consumer.assignment();
}
Map<TopicPartition, Long> timestampToSearch=new HashMap<>();
for(TopicPartition topicPartition:assignment){
// 消费一天之前的消息
timestampToSearch.put(topicPartition,System.currentTimeMillis()-24*3600*1000);
}
// 获取指定时间之后的分区消息位置
Map<TopicPartition, OffsetAndTimestamp> offsets=consumer.offsetsForTimes(timestampToSearch);
for(TopicPartition topicPartition:assignment){
OffsetAndTimestamp offsetAndTimestamp=offsets.get(topicPartition);
if(offsetAndTimestamp!=null){
consumer.seek(topicPartition,offsetAndTimestamp.offset());
}
}
while(isRunning.get()){
ConsumerRecords<String, String> records=consumer.poll(Duration.ofMillis(1000));
for(ConsumerRecord<String, String> record:records){
System.out.println(record.offset()+":"+record.value());
}
}
}
如果 seek() 方法指定的分区位置无法在实际的分区中找到,则会发生位移越界,触发 auto.offset.reset 的执行。
此外,Kafka的消费位移是存储在一个内部主题中的,使用 seek()
方法可以突破这一限制,将其保存到数据库、文件系统等。以数据库为例,可以将消费位移保存到一个表中,在下次消费的时候可以读取存储在数据库表中的消费位移,并通过 seek() 方法指向这个具体的位置。
public static void main(String[]args){
Properties properties=initConfig();
KafkaConsumer<String, String> consumer=new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList(TOPIC));
Set<TopicPartition> assignment=new HashSet<>();
while(assignment.size()==0){
consumer.poll(Duration.ofMillis(100));
assignment=consumer.assignment();
}
for(TopicPartition topicPartition:assignment){
// 从DB获取消费位移
long offset=getOffsetFromDB(topicPartition);
consumer.seek(topicPartition,offset);
}
while(isRunning.get()){
ConsumerRecords<String, String> records=consumer.poll(Duration.ofMillis(1000));
for(TopicPartition partition:records.partitions()){
List<ConsumerRecord<String, String>>partitionRecords=records.records(partition);
for(ConsumerRecord<String, String> partitionRecord:partitionRecords){
System.out.println(partitionRecord.offset()+":"+partitionRecord.value());
}
long lastConsumedOffset=partitionRecords.get(partitionRecords.size()-1).offset();
// 将消费位移保存到DB
storeOffsetToDB(partition,lastConsumedOffset+1);
}
}
}
/**
* 保存消费位移到DB
*/
private static void storeOffsetToDB(TopicPartition partition,long position){
}
/**
* 从数据库中获取消费位移
*/
private static long getOffsetFromDB(TopicPartition topicPartition){
return 0;
}
四、总结
以上是在阅读《深入理解Kafka核心设计与实践原理》这本书时对Kafka消费位移管理的梳理总结,在实际使用Kafka客户端消费消息的过程中,了解以上内容有利于我们对消息的消费和位移的提交进行更精确的控制。
参考